¶ Про мониторинг в 300 проекте
Шина данных в большей степени инфраструктурный сервис, предполагающий бесперебойное функционирование.
В МИЭМе, и в проектной среде в частности, мы часто слышим про DevOps как методологию разработки, предполагающую как свои основные пункты:
- Непрерывную интеграцию
- Непрерывную доставку
- Тестирование компонентов
- Контейнеризацию и обособленность компонентов
Однако часто мы упускаем довольно важный аспект DevOps методологии - мониторинг
Мы часто не думаем о том, как понять жив ли наш сервис, корректно ли он функционирует, что происходит с ресурсами, которые он использует. DevOps для нас это больше про быструю разработку и поставку проекта, однако нам безразлична дальнейшая судьба сервиса. Мы не знаем сломалось ли что-то, когда закончится место у базы данных и многое другое. Мы не отслеживаем метрики сервиса, как итог - не всегда можем сделать вывод чем вообще сервис полезен в нашей среде.
В нашем проекте мы в большей степени думали о том, что будет после того, как мы передадим его в дальнейшие руки цифрового следа. Нам нужно было чтобы:
- Сервисы можно было доработать для их нужд
- Можно было оценить то, как работают сервисы
- Где наши сервисы ломаются
Для того чтобы решать все эти задачи существует множество решений, но все они сводятся к тому, чтобы настроить, а в нашем случае - предоставить средства для настройки, мониторинг сервисов с помощью готовых и проверенных решений, таких как Prometheus и Grafana. Оба решения являются open-source, прекрасно работают вместе и предоставляют инструменты для быстрого и удобного развёртывания.
¶ Кратко про Grafana
Grafana - open-source система для визуализации данных, позволяет создавать различного вида панели, отображающие различные статистики и графики. Интегрируется с СУБД временных рядов и дополняется различными плагинами (алёртинг, новые виды досок и тд).
¶ Кратко про Prometheus
Prometheus - open-source система, состоящая из модуля алёртинга, СУБД временных рядов и системы сбора метрик через http-pull модель. Позволяет задавать цели для сбора данных и конфигурацию, определяющую частоту сбора "метрик" - специальных единиц данных, отражающих значение или изменение некоторой величины в определённый момент времени. Позволяет делать запросы по метрикам используя свой язык PromQL.
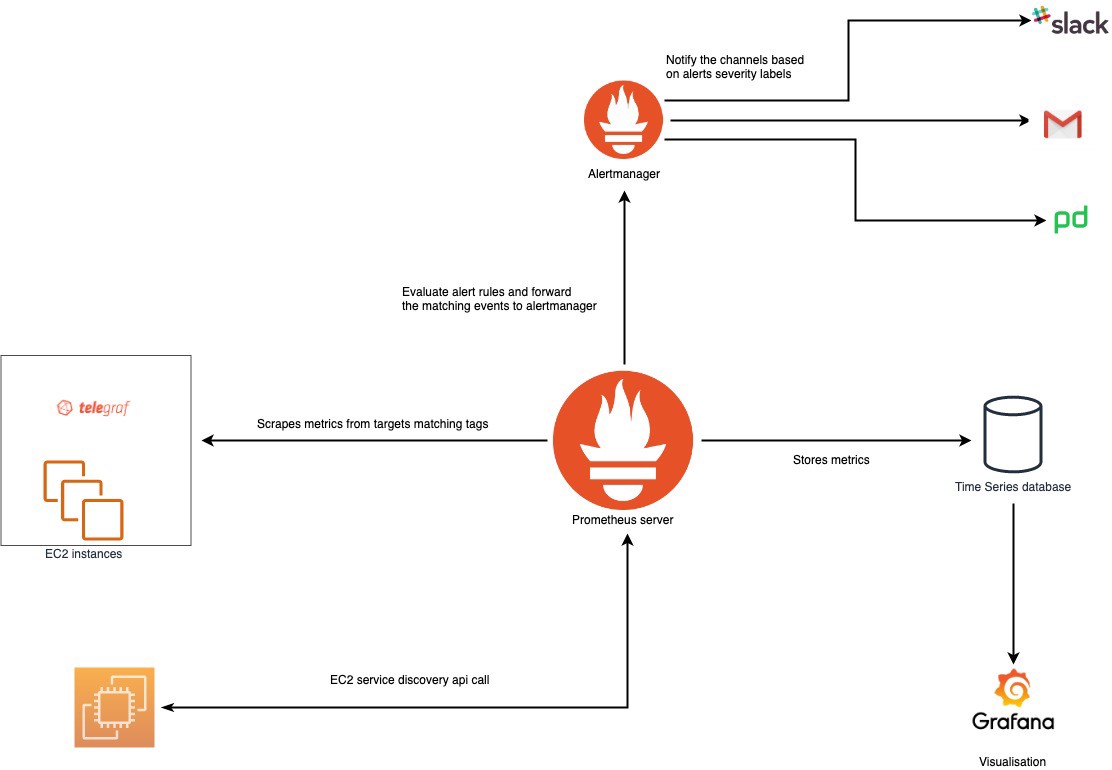
¶ Как мы используем это в нашем проекте
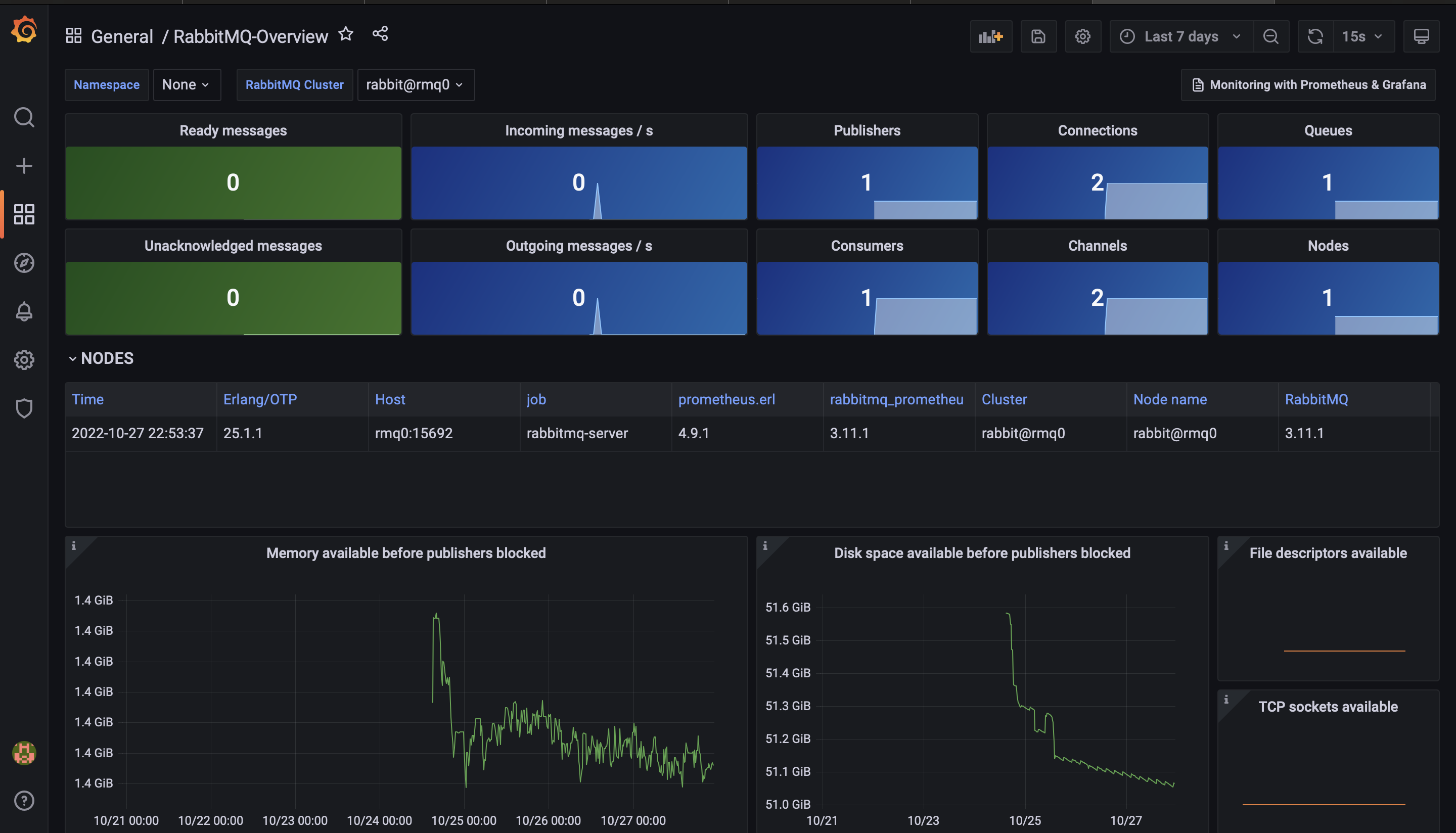
Для мониторинга текущего состояния кластера RabbitMQ, а также сервисов шины данных, в проекте были написаны docker-compose файлы, для развёртывания сервисов для мониторинга с предустановленными досками для RabbitMQ. Конфигурация совместима с аналогичной для развёртывания кластера брокера сообщений, а также описано руководство о том, как добавить в существующую инфраструктуру новые сервисы, предоставляющие метрики и нуждающиеся в мониторинге.
Мы осознанно отказались от алёртинга, так как его основной смысл в том, чтобы оповещать дежурного о том, что что-то не так. Однако мы всё-таки являемся студентами и у нас нет практики полноценных 24-часовых дежурств. В дальнейшем при желании в текущую архитектуру можно легко подключить алёртинг через Prometheus.
Пример доски для RabbitMQ